Approach
General Idea
- Load the data graph from disk (gzipped, n-triple files)
- Parse the RDF graph into a spark labeled property graph
- Phase 0: partition the graph by a random vertex cut such that vertices and their outgoing (or incoming edges for undirected graphs) are in the same partition.
- Phase 1.1: each vertex computes its own local schema based on vertex label and edge label
- Phase 1.2: signal and collect the neighbor information to construct complex schemas
- Phase 2: write the graph to OrientDB, merge on collision.
If incremental computation is used, skip step 6 (phase 2) for all unchanged vertices.
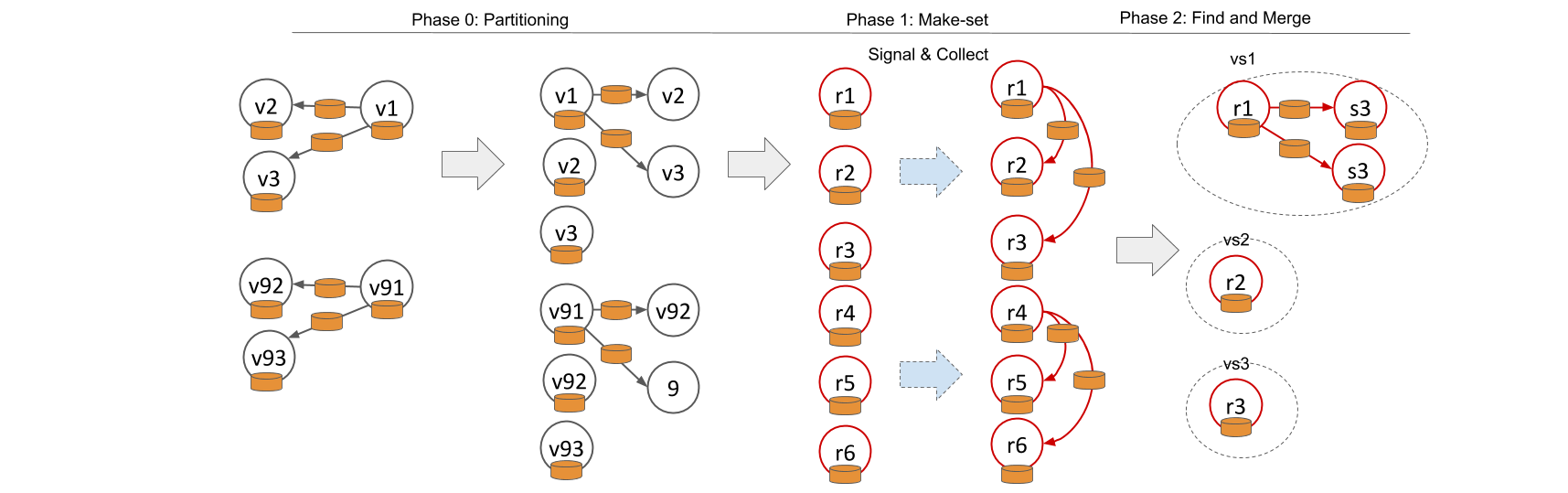 Figure 1: Visualizing the idea of the algorithm. Label ofvertices and edges are represented by orange shapes.
Figure 1: Visualizing the idea of the algorithm. Label ofvertices and edges are represented by orange shapes.